分布式及其它
数据库和缓存双写一致性方案解析:https://www.cnblogs.com/rjzheng/p/9041659.html
高可用分布式集群
一,高可用
高可用(High Availability),是当一台服务器停止服务后,对于业务及用户毫无影响。 停止服务的原因可能由于网卡、路由器、机房、CPU负载过高、内存溢出、自然灾害等不可预期的原因导致,在很多时候也称单点问题。
(1)解决单点问题主要有2种方式:
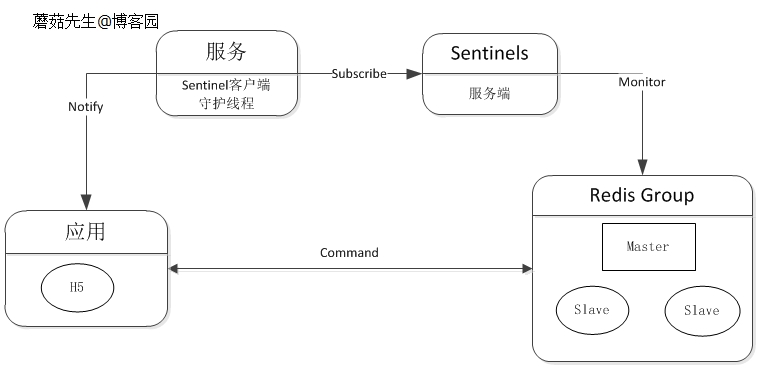
主备方式 这种通常是一台主机、一台或多台备机,在正常情况下主机对外提供服务,并把数据同步到备机,当主机宕机后,备机立刻开始服务。 Redis HA中使用比较多的是keepalived,它使主机备机对外提供同一个虚拟IP,客户端通过虚拟IP进行数据操作,正常期间主机一直对外提供服务,宕机后VIP自动漂移到备机上。
优点是对客户端毫无影响,仍然通过VIP操作。 缺点也很明显,在绝大多数时间内备机是一直没使用,被浪费着的。
主从方式 这种采取一主多从的办法,主从之间进行数据同步。 当Master宕机后,通过选举算法(Paxos、Raft)从slave中选举出新Master继续对外提供服务,主机恢复后以slave的身份重新加入。 主从另一个目的是进行读写分离,这是当单机读写压力过高的一种通用型解决方案。 其主机的角色只提供写操作或少量的读,把多余读请求通过负载均衡算法分流到单个或多个slave服务器上。
缺点是主机宕机后,Slave虽然被选举成新Master了,但对外提供的IP服务地址却发生变化了,意味着会影响到客户端。 解决这种情况需要一些额外的工作,在当主机地址发生变化后及时通知到客户端,客户端收到新地址后,使用新地址继续发送新请求。
(2)数据同步 无论是主备还是主从都牵扯到数据同步的问题,这也分2种情况:
同步方式:当主机收到客户端写操作后,以同步方式把数据同步到从机上,当从机也成功写入后,主机才返回给客户端成功,也称数据强一致性。 很显然这种方式性能会降低不少,当从机很多时,可以不用每台都同步,主机同步某一台从机后,从机再把数据分发同步到其他从机上,这样提高主机性能分担同步压力。 在redis中是支持这杨配置的,一台master,一台slave,同时这台salve又作为其他slave的master。
异步方式:主机接收到写操作后,直接返回成功,然后在后台用异步方式把数据同步到从机上。 这种同步性能比较好,但无法保证数据的完整性,比如在异步同步过程中主机突然宕机了,也称这种方式为数据弱一致性。
Redis主从同步采用的是异步方式,因此会有少量丢数据的危险。还有种弱一致性的特例叫最终一致性,这块详细内容可参见CAP原理及一致性模型。
(3)方案选择 keepalived方案配置简单、人力成本小,在数据量少、压力小的情况下推荐使用。 如果数据量比较大,不希望过多浪费机器,还希望在宕机后,做一些自定义的措施,比如报警、记日志、数据迁移等操作,推荐使用主从方式,因为和主从搭配的一般还有个管理监控中心。
宕机通知这块,可以集成到客户端组件上,也可单独抽离出来。 Redis官方Sentinel支持故障自动转移、通知等,详情见低成本高可用方案设计(四)。
逻辑图:
二,分布式
分布式(distributed), 是当业务量、数据量增加时,可以通过任意增加减少服务器数量来解决问题。
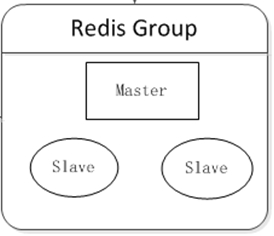
集群时代 至少部署两台Redis服务器构成一个小的集群,主要有2个目的:
高可用性:在主机挂掉后,自动故障转移,使前端服务对用户无影响。 读写分离:将主机读压力分流到从机上。 可在客户端组件上实现负载均衡,根据不同服务器的运行情况,分担不同比例的读请求压力。
逻辑图:
三,分布式集群时代
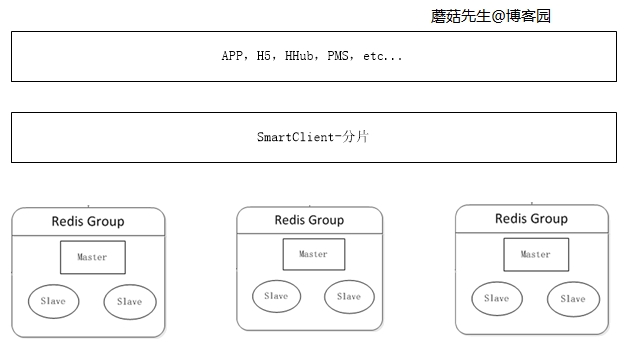
当缓存数据量不断增加时,单机内存不够使用,需要把数据切分不同部分,分布到多台服务器上。 可在客户端对数据进行分片,数据分片算法详见C#一致性Hash详解、C#之虚拟桶分片。
逻辑图:
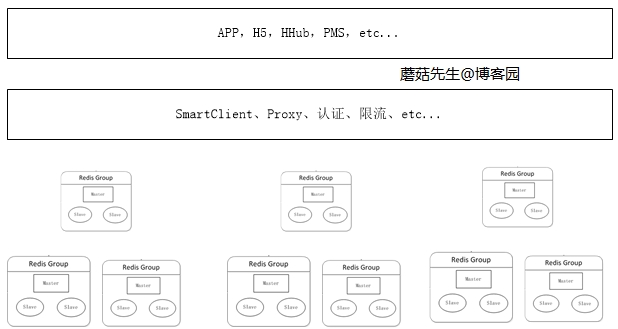
大规模分布式集群时代 当数据量持续增加时,应用可根据不同场景下的业务申请对应的分布式集群。 这块最关键的是缓存治理这块,其中最重要的部分是加入了代理服务。 应用通过代理访问真实的Redis服务器进行读写,这样做的好处是:
避免越来越多的客户端直接访问Redis服务器难以管理,而造成风险。 在代理这一层可以做对应的安全措施,比如限流、授权、分片。 避免客户端越来越多的逻辑代码,不但臃肿升级还比较麻烦。 代理这层无状态的,可任意扩展节点,对于客户端来说,访问代理跟访问单机Redis一样。 目前楼主公司使用的是客户端组件和代理两种方案并存,因为通过代理会影响一定的性能。 代理这块对应的方案实现有Twitter的Twemproxy和豌豆荚的codis。
逻辑图:
四,总结
分布式缓存再向后是云服务缓存,对使用端完全屏蔽细节,各应用自行申请大小、流量方案即可,如淘宝OCS云服务缓存。 分布式缓存对应需要的实现组件有:
一个缓存监控、迁移、管理中心。 一个自定义的客户端组件,上图中的SmartClient。 一个无状态的代理服务。 N台服务器。
25、Redis中的管道有什么用?
一次请求/响应服务器能实现处理新的请求即使旧的请求还未被响应。这样就可以将多个命令发送到服务器,而不用等待回复,最后在一个步骤中读取该答复。
这就是管道(pipelining),是一种几十年来广泛使用的技术。例如许多POP3协议已经实现支持这个功能,大大加快了从服务器下载新邮件的过程。
26、怎么理解Redis事务?
事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
27、Redis事务相关的命令有哪几个?
MULTI、EXEC、DISCARD、WATCH
28、Redis key的过期时间和永久有效分别怎么设置?
EXPIRE和PERSIST命令。
29、Redis如何做内存优化?
尽可能使用散列表(hashes),散列表(是说散列表里面存储的数少)使用的内存非常小,所以你应该尽可能的将你的数据模型抽象到一个散列表里面。
比如你的web系统中有一个用户对象,不要为这个用户的名称,姓氏,邮箱,密码设置单独的key,而是应该把这个用户的所有信息存储到一张散列表里面。
30、Redis回收进程如何工作的?
一个客户端运行了新的命令,添加了新的数据。
Redi检查内存使用情况,如果大于maxmemory的限制, 则根据设定好的策略进行回收。
一个新的命令被执行,等等。
所以我们不断地穿越内存限制的边界,通过不断达到边界然后不断地回收回到边界以下。
如果一个命令的结果导致大量内存被使用(例如很大的集合的交集保存到一个新的键),不用多久内存限制就会被这个内存使用量超越。
如何解决缓存雪崩?
是什么?
a、Redis挂掉了,请求全部走数据库。 b、对缓存数据设置相同的过期时间,导致某段时间内缓存失效,请求全部走数据库。
怎么解决?
对于B的情况,在缓存的时候给过期时间加上一个随机值,这样就会大幅度的减少缓存在同一时间过期。
对于A的情况:
事发前:实现Redis的高可用(主从架构+Sentinel 或者Redis Cluster),尽量避免Redis挂掉这种情况发生。
事发中:万一Redis真的挂了,我们可以设置本地缓存(ehcache)+限流(hystrix),尽量避免我们的数据库被干掉(起码能保证我们的服务还是能正常工作的)
事发后:redis持久化,重启后自动从磁盘上加载数据,快速恢复缓存数据。
解决方法
加锁排队. 限流-- 限流算法. 1.计数 2.滑动窗口 3. 令牌桶Token Bucket 4.漏桶 leaky bucket [1]
在缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
业界比较常用的做法,是使用mutex。简单地来说,就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db,而是先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX或者Memcache的ADD)去set一个mutex key,当操作返回成功时,再进行load db的操作并回设缓存;否则,就重试整个get缓存的方法。
SETNX,是「SET if Not eXists」的缩写,也就是只有不存在的时候才设置,可以利用它来实现锁的效果。
2.数据预热可以通过缓存reload机制,预先去更新缓存,再即将发生大并发访问前手动触发加载缓存不同的key,设置不同的过期时间,让缓存失效的时间点尽量均匀
3.做二级缓存,或者双缓存策略。
A1为原始缓存,A2为拷贝缓存,A1失效时,可以访问A2,A1缓存失效时间设置为短期,A2设置为长期。 4.缓存永远不过期这里的“永远不过期”包含两层意思:
\(1\) 从缓存上看,确实没有设置过期时间,这就保证了,不会出现热点key过期问题,也就是“物理”不过期。 \(2\) 从功能上看,如果不过期,那不就成静态的了吗?所以我们把过期时间存在key对应的value里,如果发现要过期了,通过一个后台的异步线程进行缓存的构建,也就是“逻辑”过期.从实战看,这种方法对于性能非常友好,唯一不足的就是构建缓存时候,其余线程(非构建缓存的线程)可能访问的是老数据,但是对于一般的互联网功能来说这个还是可以忍受。
如何解决缓存穿透?
是什么?
请求的数据在缓存大量不命中,导致请求走数据库。 缓存穿透是指查询一个一定不存在的数据。由于缓存不命中,并且出于容错考虑,如果从数据库查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,失去了缓存的意义。
怎么解决?
解决缓存穿透也有两种方案:
a、由于请求的参数是不合法的(每次都请求不存在的参数),于是我们可以使用布隆过滤器(BloomFilter)或者压缩filter提前拦截,不合法就不让这个请求到数据库层!
b、当我们从数据库找不到的时候,我们也将这个空对象设置到缓存里边去。下次再请求的时候,就可以从缓存里边获取了。
c、这种情况我们一般会将空对象设置一个较短的过期时间。
解决办法:
1.布隆过滤对所有可能查询的参数以hash形式存储,在控制层先进行校验,不符合则丢弃。还有最常见的则是采用布隆过滤器,将所有可能存在的数据哈希到一个足够大的bitmap中,一个一定不存在的数据会被这个bitmap拦截掉,从而避免了对底层存储系统的查询压力。
补充:
Bloom filter适用范围:可以用来实现数据字典,进行数据的判重,或者集合求交集
基本原理及要点:对于原理来说很简单,位数组+k个独立hash函数。将hash函数对应的值的位数组置1,查找时如果发现所有hash函数对应位都是1说明存在,很明显这个过程并不保证查找的结果是100%正确的。同时也不支持删除一个已经插入的关键字,因为该关键字对应的位会牵动到其他的关键字。所以一个简单的改进就是counting Bloom filter,用一个counter数组代替位数组,就可以支持删除了。添加时增加计数器,删除时减少计数器。
缓存空对象. 将 null 变成一个值.
也可以采用一个更为简单粗暴的方法,如果一个查询返回的数据为空(不管是数据不存在,还是系统故障),我们仍然把这个空结果进行缓存,但它的过期时间会很短,最长不超过五分钟。
缓存空对象会有两个问题:
第一,空值做了缓存,意味着缓存层中存了更多的键,需要更多的内存空间 ( 如果是攻击,问题更严重 ),比较有效的方法是针对这类数据设置一个较短的过期时间,让其自动剔除。
第二,缓存层和存储层的数据会有一段时间窗口的不一致,可能会对业务有一定影响。例如过期时间设置为 5分钟,如果此时存储层添加了这个数据,那此段时间就会出现缓存层和存储层数据的不一致,此时可以利用消息系统或者其他方式清除掉缓存层中的空对象。
如何保证缓存与数据库双写时一致的问题?
1、不一致产生的原因?
我们在是使用redis过程中,通常会这样做,先读取缓存,如果缓存不存在,则读取数据库。
不管是先写库,再删除缓存;还是先删除缓存,再写库,都有可能出现数据不一致的情况。
因为写和读是并发的,没法保证顺序,如果删除了缓存,还没有来得及写库,另一个线程就来读取,发现缓存为空,则去数据库中读取数据写入缓存,此时缓存中为脏数据。如果先写了库,在删除缓存前,写库的线程宕机了,没有删除掉缓存,则也会出现数据不一致情况。
如果是redis集群,或者主从模式,写主读从,由于redis复制存在一定的时间延迟,也有可能导致数据不一致。
1.常规简单的解决方案
先删除缓存,在更新数据库,如果删除缓存成功,修改数据库失败了,那么数据库中依然是旧数据,如果去读取数据的时候,发现缓存没有,则去读数据库,数据库会把旧数据加载到缓存里,这样缓存和数据库则保持了一致。
2.如果在高并发的情况下会发生了如下更复杂的操作
比如有数据发生了变更,先删除了缓存,然后准备要去修改数据库,此时还没修改,这时候一个请求过来,去读缓存,发现缓存空了,去查询数据库,查到了修改前的旧数据,放到了缓存中 ,之后数据变更的程序完成了数据库的修改。完了,数据库和缓存中的数据不一样了。。。
解决方案:
3.内存队列
更新数据的时候,根据数据的唯一标识,将操作路由之后,发送到一个jvm内部的队列中,读取数据的时候,如果发现数据不在缓存中,那么将重新读取数据+更新缓存的操作,根据唯一标识路由之后,也发送同一个jvm内部的队列中
一个队列对应一个工作线程,每个工作线程串行拿到对应的操作,然后一条一条的执行。这样的话,一个数据变更的操作,先执行删除缓存,然后再去更新数据库,但是还没完成更新。此时如果一个读请求过来,读到了空的缓存,那么可以先将缓存更新的请求发送到队列中,此时会在队列中积压,然后同步等待缓存更新完成
这里有一个优化点,一个队列中,其实多个更新缓存请求串在一起是没意义的,因此可以做过滤,如果发现队列中已经有一个更新缓存的请求了,那么就不用再放个更新请求操作进去了,直接等待前面的更新操作请求完成即可,待那个队列对应的工作线程完成了上一个操作的数据库的修改之后,才会去执行下一个操作,也就是缓存更新的操作,此时会从数据库中读取最新的值,然后写入缓存中。如果请求还在等待时间范围内,不断轮询发现可以取到值了,那么就直接返回; 如果请求等待的时间
超过一定时长,那么这一次直接从数据库中读取当前的旧值。
Last updated
Was this helpful?